
Base de datos
Flujo de trabajo proyecto PortADa
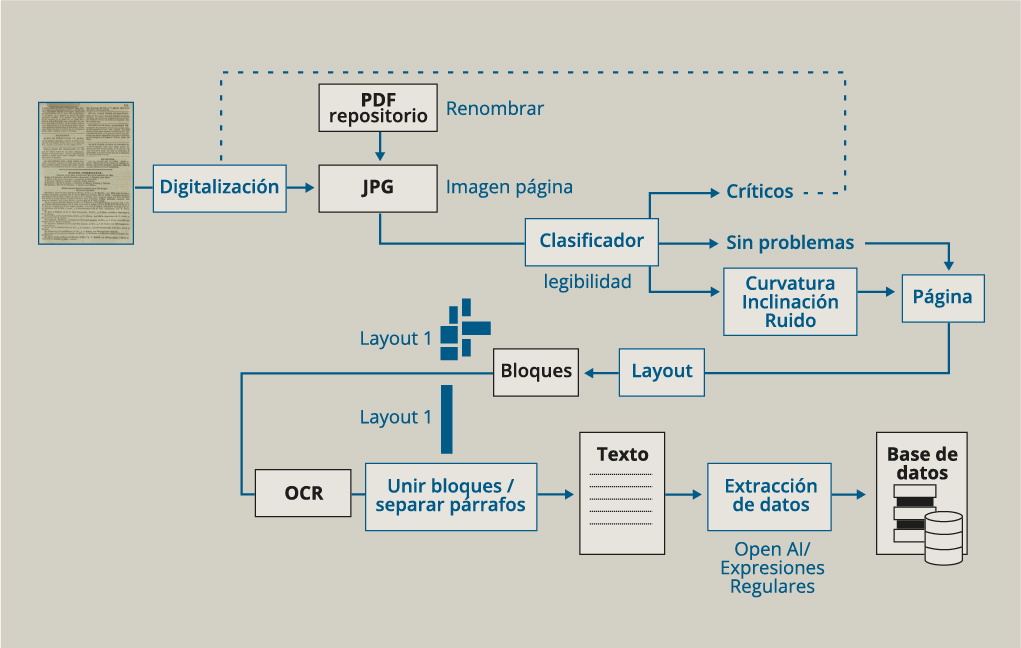
Cómo se construye la base de datos de PortADa
El proyecto se nutre de la información que la prensa local de cada ciudad-puerto publicó sobre la llegada de barcos procedentes de diversos destinos. Para Barcelona (España), Marsella (Francia) y La Habana (Cuba), la mayoría de las fuentes se encontraban digitalizadas en repositorios de hemerografía digital histórica.
Las imágenes, que en algunos casos estaban en formato .pdf, fueron transformadas a .jpg. Para Buenos Aires (Argentina), ante la falta de fondos digitalizados, se fotografió la información de interés para el proyecto.
El nombre de las imágenes se normalizó considerando los siguientes metadatos: fecha de publicación, nombre del periódico, edición, número del diario, posición, página y segmento.
Tras la digitalización, el flujo de trabajo pasa por cuatro etapas: corrección, layout, reconocimiento óptico de caracteres (OCR) y extracción de datos.
Para elegir los métodos más apropiados en cada fase del trabajo, se realizaron ejercicios de prueba con diferentes herramientas. Todos los procesos seleccionados se han integrado en un software denominado PAPICLI, que permite a personas sin conocimientos técnicos realizar de forma autónoma cada una de las fases del flujo de trabajo.
Las imágenes con las que trabajamos deben ser de alta calidad y lo suficientemente nítidas para que las letras y los números puedan distinguirse con claridad. A partir de redes neuronales profundas (modelo ResNet), se elaboró un clasificador automático que diferencia las imágenes críticas —que deberán ser digitalizadas nuevamente— de aquellas que serán útiles para nuestro trabajo. A las imágenes útiles se les aplicó un software discriminador que las separaba según los principales problemas detectados para el trabajo de OCR: curvatura, ruido e inclinación.
Esta separación permite aplicar una solución específica para cada imagen. La mayor parte del material digitalizado se presenta en forma de páginas completas; sin embargo, nos interesan las noticias de arribos, que solo ocupan una parte de esas páginas. Por tal razón, una vez corregidas las imágenes, se inicia el trabajo de layout, que apunta a segmentar la imagen del periódico en bloques (secciones, columnas, párrafos).
Para este objetivo se han utilizado, alternativamente, el algoritmo YOLO (You Only Look Once) y la Newspaper Segmentation API de Arcanum. Con las imágenes segmentadas, aplicamos el procedimiento de OCR, para lo cual utilizamos Document AI de Google.
Tras el reconocimiento automático de caracteres, unimos los párrafos para reconstruir la noticia de entradas de barcos publicada para cada día y cada periódico. Seguidamente, cada entrada de buque se separaba en una línea diferente.
Con ese material se realiza la extracción de datos para completar nuestra base de datos. Utilizamos expresiones regulares y OpenAI para que los datos incluidos en la noticia puedan organizarse según los diversos campos de extracción que hemos definido.
